近期,OpenAI发布了其GPT模型的最新旗舰版本5.2,并展示了大量在不同大模型测评标准中刷新高分显示其超越人类专家、无可比拟的专业知识工作表现。但出乎所有人意料之外,新模型一经上线就引发了大量差评。用户纷纷晒出各种截图挖苦GPT这次不但在很多常识推理、多模态交互、代码生产的场景中不如其竞争对手Claude和Gemini,更有人指出在一些常见的场景下,5.2的表现甚至不如自己一年前甚至更早的版本。我们不禁要问:从大模型爆火到现在不过几年,AI的发展已经到达瓶颈了吗?
一个模型,两种智商
面对大模型厂商不断刷新榜单高分的宣发,普通用户们似乎开始不再买账。厂商们在模型推陈出新的过程中像是期末大考得了高分挥舞着榜单分数,而用户们却竞相拿出他们日常交互时的降智梗图。
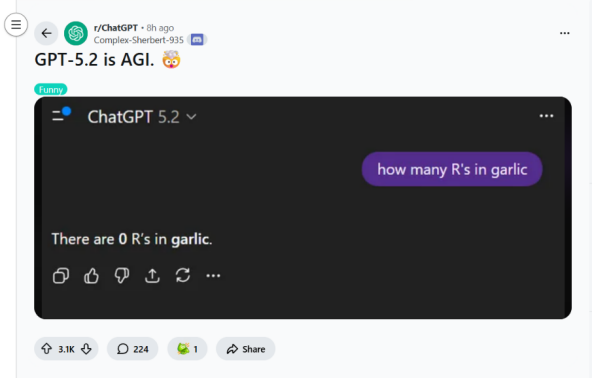
越来越多人发现榜单测评的数据和日常使用的体验之间存在着巨大的鸿沟。一方面厂商标榜AI已经可以比肩各领域顶级的人类专家;而另一方面,用户却看到AI在非常低级的常识问题上稳定翻车。所有人都已经对这种割裂习以为常。
顶级研究员还是生产力工具?
厂商执着于打榜是因为榜单往往可以反映出模型技术能力的上限,这在科研技术层面当然是完全合乎逻辑的;而用户在日常使用过程中对于模型的感知则几乎完全来自其下限,这其中天然存在着难以调和的冲突。
在榜单测评的过程中,大模型主要测试极限场景下面向明确目标独立执行的表现,且使用固定静态的测试数据采用标准答案进行可量化的横向对比;但对于用户日常的使用来说,需要的是能根据上下文对于简单但模糊多变的场景输出稳定可靠的结果。

虽然OpenAI作为AI大模型厂商中的佼佼者预计2025全量收入超过100亿美元,但由于模型训练和运营的天量支出,使其在今年第三季度便可能面临120亿美元的巨额亏损。山大的商业压力使得厂商们开始在这场AI军备竞赛中往争夺上限的方向孤注一掷,期望尽早抢占AGI(通用人工智能)的山头。
用户想要可靠的生产力工具解决实际问题,而厂商却一心想让AI变成顶级研究员获取商业成功。在不断亲身实践的过程中,用户已经对厂商宣发中描绘的“大饼”彻底祛魅。
结语
市场对于GPT-5.2的一系列负面反应并不意味着现在的AI就已经遇到了发展的瓶颈,这实际上是对AI发展与实践应用之间的深刻裂痕的又一次警示。无论AI在榜单上有多“夯”,在实践过程中我们还是会发现它实际“拉”得有些莫名其妙。未来AI发展的挑战不仅仅是对于少数极限复杂场景的能力提升,更在于对各种琐碎场景的深刻理解和对随机模糊需求的精准对接和有效输出。毕竟,绝大多数个人和企业用户对于AI的要求并不是占领榜单的聪明绝顶,而是实际应用的稳定可靠。