Recently, OpenAI released the latest flagship version of its GPT model, 5.2, showcasing a large number of record-breaking high scores across various large-model benchmarks and demonstrating what it claims to be superhuman expert-level performance and unrivaled professional knowledge. However, contrary to almost everyone’s expectations, the new model triggered a wave of negative reviews almost immediately after launch.
Users began sharing screenshots mocking GPT, pointing out that this time it not only underperformed competitors such as Claude and Gemini in many scenarios involving common-sense reasoning, multimodal interaction, and code generation, but that in some everyday use cases, GPT-5.2 even performed worse than its versions from a year ago—or earlier. This inevitably raises the question: only a few years after large models first exploded in popularity, has AI development already hit a bottleneck?
One Model, Two IQs
Faced with vendors constantly advertising ever-higher benchmark scores, ordinary users seem increasingly unconvinced. Model providers wave their benchmark rankings like stellar final-exam results, while users respond by circulating memes about “AI losing intelligence” based on their everyday interactions.
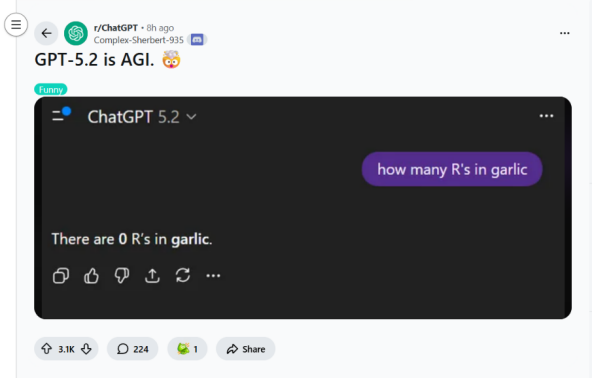
More and more people are realizing that there is a huge gap between benchmark evaluation results and real-world user experience. On the one hand, vendors claim AI can rival top human experts across domains; on the other, users see AI consistently stumble over extremely basic common-sense questions. Everyone has become accustomed to this sharp disconnect.
Top Researcher or Productivity Tool?
Vendors’ obsession with rankings stems from the fact that benchmarks often reflect the upper bound of a model’s technical capabilities, which indeed makes perfect sense from a research perspective. Users’ perception of a model in daily use, however, is shaped almost entirely by its lower bound—creating an inherent and hard-to-reconcile conflict.
In benchmark evaluations, large models are primarily tested on extreme scenarios, performing independently toward clearly defined goals, using fixed and static test datasets with standard answers that allow for quantitative comparisons. In everyday use, by contrast, users need models that can produce stable and reliable outputs in simple but ambiguous, ever-changing scenarios, based on context.

Although OpenAI, as one of the leading large-model vendors, is expected to surpass $10 billion in total revenue in 2025, the enormous costs of training and operating these models mean it could still face losses of up to $12 billion as early as the third quarter of this year. Under immense commercial pressure, vendors are going all-in on competing for the upper limits of model capability in this AI arms race, hoping to seize the high ground of AGI (artificial general intelligence) as early as possible.
Users want reliable productivity tools to solve real problems, while vendors are focused on turning AI into top-tier researchers to achieve commercial success. Through repeated hands-on experience, users have become thoroughly disenchanted with the grand promises painted by vendor marketing.
Conclusion
The market’s negative reaction to GPT-5.2 does not mean that AI has already hit a developmental ceiling. Rather, it is another warning sign highlighting the deep rift between AI development and real-world application. No matter how “impressive” AI may look on leaderboards, in practice it often turns out to be puzzlingly “underwhelming.”
The future challenge for AI development lies not only in boosting performance on a handful of extremely complex edge cases, but also in deeply understanding countless mundane scenarios and accurately responding to random, fuzzy requirements with effective outputs. After all, what most individual and enterprise users want from AI is not record-breaking brilliance on benchmarks, but stable and reliable performance in real-world use.